Implementing AI in life sciences research presents both significant opportunities and real challenges. While AI and machine learning promise to accelerate discoveries and improve outcomes, biotech organizations must also address data quality, error propagation, governance, compliance, and pipeline reliability before these tools can be trusted and effective. A foundational step in realizing AI’s potential is building AI-safe data pipelines that ensure consistent, accurate, and regulated data for downstream models.

Key Takeaways
- Build biotech pipelines to keep data traceable, validated, and reproducible end to end
- Catch issues early so small errors do not poison downstream datasets or models
- Use clear standards (schema, naming, access, versioning) to make AI outputs safer
Who this is for
-
Biotech data and platform teams building AI-ready pipelines
-
ML and data science teams relying on high-integrity datasets
-
Ops, IT, and compliance leaders responsible for governance and auditability
How can life sciences data analytics improve healthcare outcomes?
Life sciences data analytics can improve healthcare outcomes by enabling faster insights, more accurate predictions, and better decision-making across research, development, and clinical operations. These benefits depend on the quality, consistency, and governance of the underlying data.
In regulated biotech environments, analytics initiatives often fall short not because of limitations in analytics or AI models, but because data pipelines introduce errors, inconsistencies, or compliance risks. When data is incomplete, poorly governed, or difficult to trace, downstream analytics cannot be trusted.
AI-safe data pipelines address these challenges by enforcing data validation, access controls, lineage, and auditability before analytics and machine learning are applied. This foundation allows organizations to improve healthcare outcomes while maintaining data integrity and regulatory compliance.
How is data analytics transforming research in life sciences?
Data analytics is transforming life sciences research by enabling organizations to analyze larger, more complex datasets across discovery, development, and manufacturing. Advanced analytics and AI can surface patterns that were previously difficult or impossible to detect, accelerating research timelines and improving reproducibility.
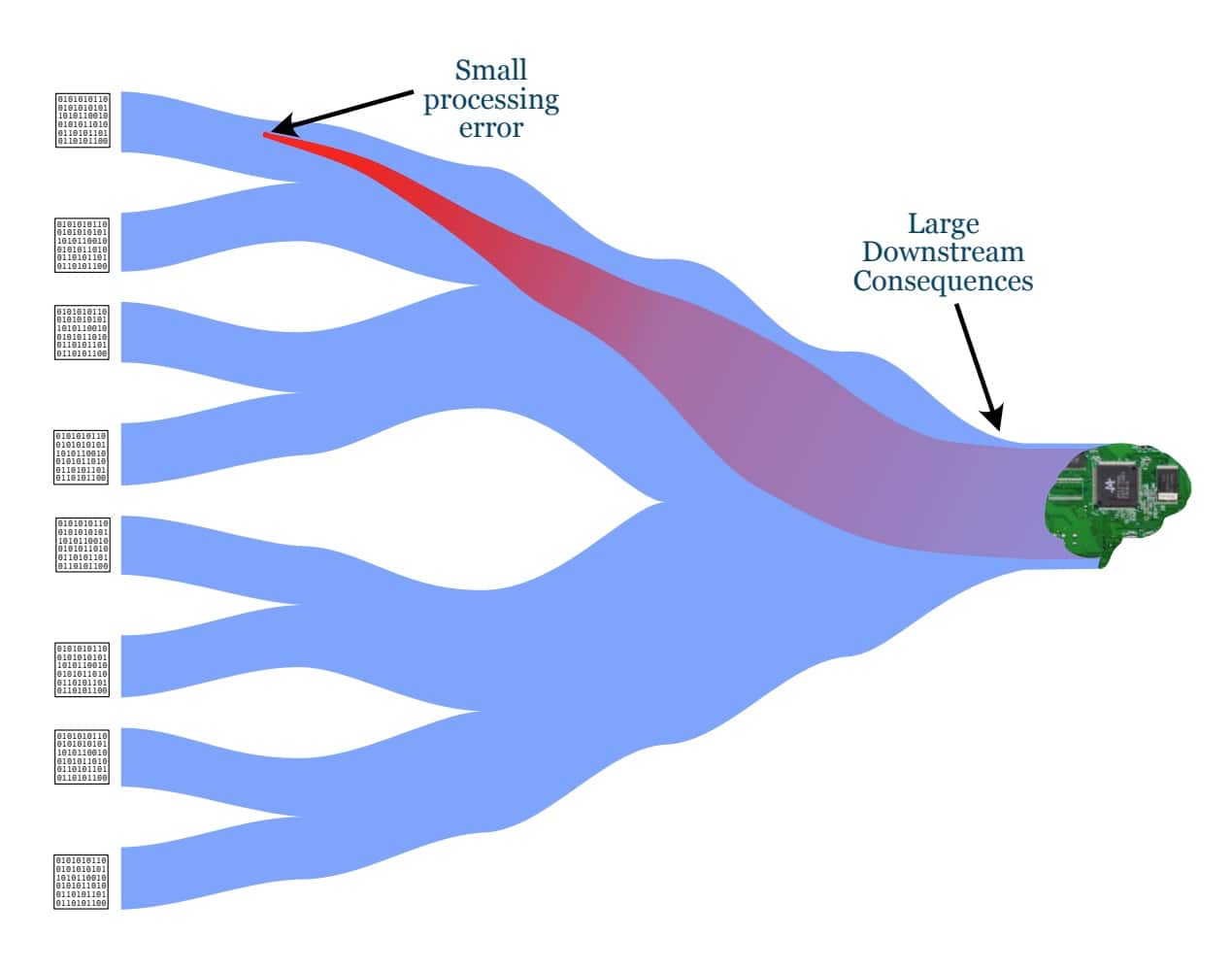
As analytics becomes more deeply embedded in research workflows, the risks associated with ungoverned data pipelines increase. Errors introduced early in the data lifecycle can propagate through models, experiments, and decision-making processes, amplifying risk rather than reducing it.
The transformation of life sciences research therefore depends not only on analytics capabilities, but on building AI-safe data pipelines that ensure data quality, traceability, and compliance throughout the research lifecycle.
Building a foundation for trustworthy AI in biotech
Analytics and AI can only deliver value when they are built on secure, governed, and reliable data pipelines. Without this foundation, organizations risk propagating errors, undermining trust, and introducing compliance challenges.
The accompanying whitepaper outlines a practical framework for building AI-safe biotech data pipelines that support compliant innovation, reproducible research, and trustworthy AI outcomes.
Frequently Asked Questions
AI-safe data describes not just high-quality data but data whose lineage, state, and transformations are observable and traceable across the pipeline so that models built from it behave predictably and safely.
Small errors in early stages like lab data collection or metadata capture can propagate and amplify through downstream processing and modeling, leading to incorrect insights or decisions if left undetected.
The white paper recommends a combination of automated validation checks, rich metadata capture, and systematic lineage tracking so issues are flagged at source and fixed cheaply before they pollute downstream datasets.
Best practices include versioning, automation of repetitive tasks, enforcing least-privilege access, intuitive data structures, documenting assumptions, and validating dependencies so pipelines are robust and traceable.
Visibility into how data flows and transforms allows teams to pinpoint where a problem originated, reducing time spent guessing and backtracking, which lowers overall cost and accelerates model iteration.
Organizations with AI-safe pipelines benefit from fewer costly downstream errors, faster onboarding of new models, better reproducibility, and stronger credibility with regulators and collaborators, all of which contribute to measurable ROI.
Learn More About AI-Safe Biotech Data Pipelines
Get guidance on building secure, governed data pipelines that support compliant AI adoption in life sciences.